自作 SEO チェッカーを自分のブログに当て続けたら何が見えたか
ちらりんブログに自作の SEO チェッカー (Python + Claude API) を 4 日連続で当てた継続観察記録。Finding 数の推移・除外ルールの効き方・crawler を本気で回したときの挙動など、自分のブログを実例にした実測ベースのログです。
はじめに
自分で作った SEO チェッカーを、まず自分のブログに当て続けています。
5 月の後半に SEO 監査用の小さなツールを Python + Claude API で書きました。きっかけは 5 月の頭に「クロール済み-インデックス未登録」の状態をひとつずつ潰した経験で、対応の半分は「同じことをもう一度起きないようにルール化したい」という気持ちでした。チェック項目を skill にまとめても、結局自分の手で月 1 回追わないと気付かない。だったらツールにしてしまおう、という流れです。
ツールができた直後の 2026-05-24 から、毎日このブログに当てています。今回はその 4 日分のレポートをそのまま素材にして、自分のブログがどう見えたか、そして「自分の作ったツールを自分のブログに当てる」という小さなループを回してみてどうだったかを書き残します。
本記事は道具の使用感の話に絞ります。ツール自体の設計思想や実装は、別途有料シリーズ (SEO チェッカー構築ガイド) にまとめています。
観察期間と条件
4 日間連続で deep_owned モード (= 自ドメイン用の詳細監査モード) を回しました。対象は https://chillablog.chillarin39.com/。収集器は robots / sitemap / page_meta / crawler / soft_404_probe / gsc / cloudflare の 7 種類です。
| 観点 | 値 |
|---|---|
| 対象ドメイン | chillablog.chillarin39.com (個人運用) |
| 監査モード | deep_owned (自ドメイン詳細監査) |
| 観察期間 | 2026-05-24 〜 2026-05-27 (4 日連続) |
| ツール | seo-checker 0.1.0 (Python + Claude API) |
| レポート出力 | json / md / pdf (途中から pptx も) |
GSC URL Inspection は途中で OAuth トークンが切れて 401 を返し続けました。この期間中の Indexed 数の経時データは取れていません。続編で扱います。
Day 1 (2026-05-24): まず深掘りなしのベースラインを取る
初日は crawler の BFS をあえて広げず、sitemap で上位に並ぶ代表 URL 6 件だけを叩く軽い回し方にしました。結果:
| 項目 | 値 |
|---|---|
| 採用 Finding | 2 件 (high 1 / info 1) |
| 除外 Finding | 8 件 |
| sitemap 掲載 URL | 323 |
| 詳細メタ抽出 | 6 URL |
採用された高優先度の指摘は 1 つだけでした。
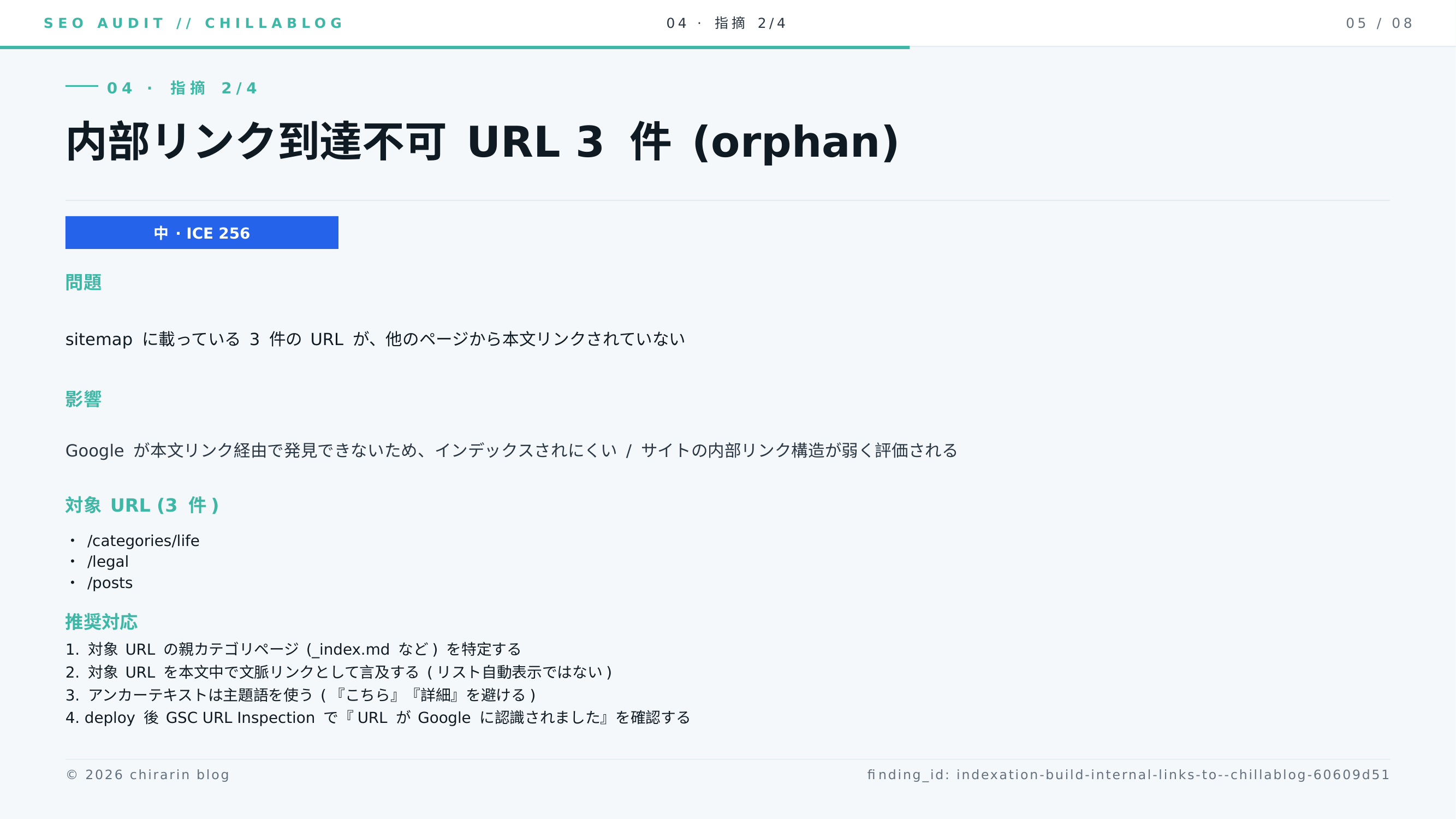
indexation / high / ICE 256: sitemap に登録されているが内部リンクから到達できない URL が 10 件 (orphan)
/apps/szta、/categories/life、/games/chillajump、/games/chillaup、/games/chiradash などが並んでいます。Hugo の section ページや独立 landing は、トップから本文リンクを張っていないと簡単に orphan になります。クローラー視点では「存在は宣言してあるが本文導線がない」という弱い状態です。
info の方は Cloudflare 経由の Googlebot 観察で、24 時間以内に WAF block 0 件・HTTP request 33 件。これは「現状維持で問題なし」の参考情報ですが、後日 BFM (Bot Fight Mode) を不用意に ON に戻さないための継続観察ラインとして残しています。
除外された 8 件はすべて「対応済み」または「誤検出」として domain_state に登録済みのものでした。内訳は description / title 長さの警告と、JSON-LD Article の存在判定の誤検出です。Hugo テンプレートで Article + Person + Organization + ImageObject を全部出している実装が、ツール側のヒューリスティックでは検知しにくい形をしていて、ここは初日にきれいに切り分けられました。
Day 2 (2026-05-25): crawler を本気で回したら 4xx と orphan が増えた
2 日目は crawler の BFS を制限なしで回しました。実際には内部上限の 100 ページで打ち切られ、合計 209 ページをクロールしています。
| 項目 | 値 |
|---|---|
| 採用 Finding | 3 件 (medium 2 / info 1) |
| 除外 Finding | 12 件 |
| クロール総ページ | 209 |
| sitemap 掲載 URL | 329 |
新しく上に出てきたのが 4xx を返す URL の指摘です。
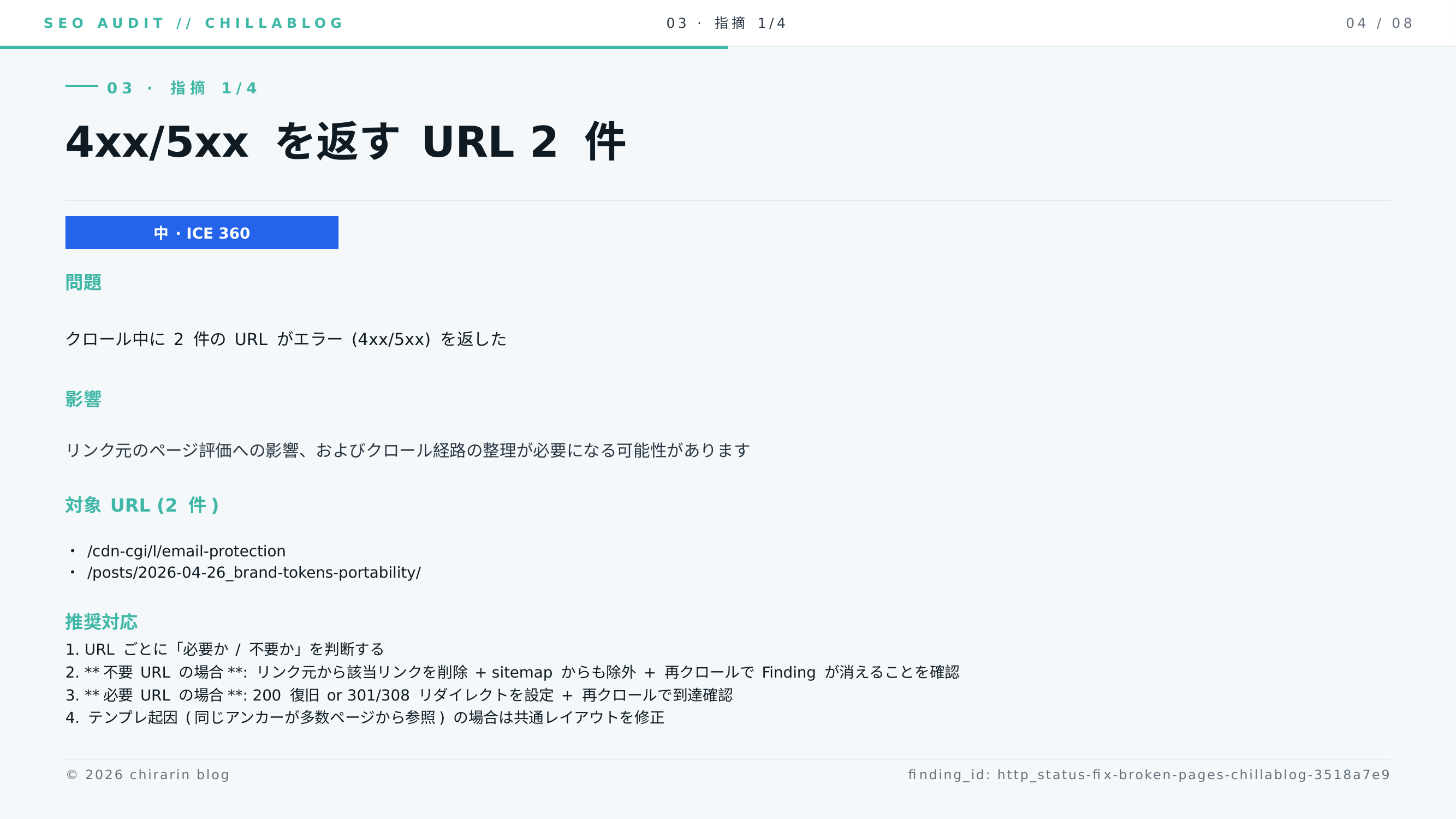
http_status / medium / ICE 360: クロール中に 4xx/5xx を返した URL が 2 件
/cdn-cgi/l/email-protection(404)/posts/2026-04-26_brand-tokens-portability/(404)
前者は Cloudflare の email obfuscation 経由のリンクが解決できていないもので、テンプレ起因で全ページから参照されています。link sources を集計してみると、参照元 42 ページの大半が指南書系のページからでした。個別ページの問題ではなく、共通レイアウトの問題が 1 個だけ立っていた、と分かったのはこの段階です。
後者は記事のリネーム (2026-04-26_brand-tokens-portability/ → 別の slug) のあとに 1 件だけ古い内部リンクが残っていたケースで、これは普通に 1 ファイル直すだけで済みます。
orphan の方は前日より減って 3 件 (/categories/life、/legal、/posts) に落ち着きました。これは crawler が BFS を伸ばしたぶんだけ「実は本文導線がある」と分かった orphan が消えた、という前向きな減り方です。1 日目の「10 件」は浅いクロールで見えていた虚像が混ざっていたわけで、ツール側の crawled_pages をレポートに必ず併記する設計にしておいて良かったところでした。
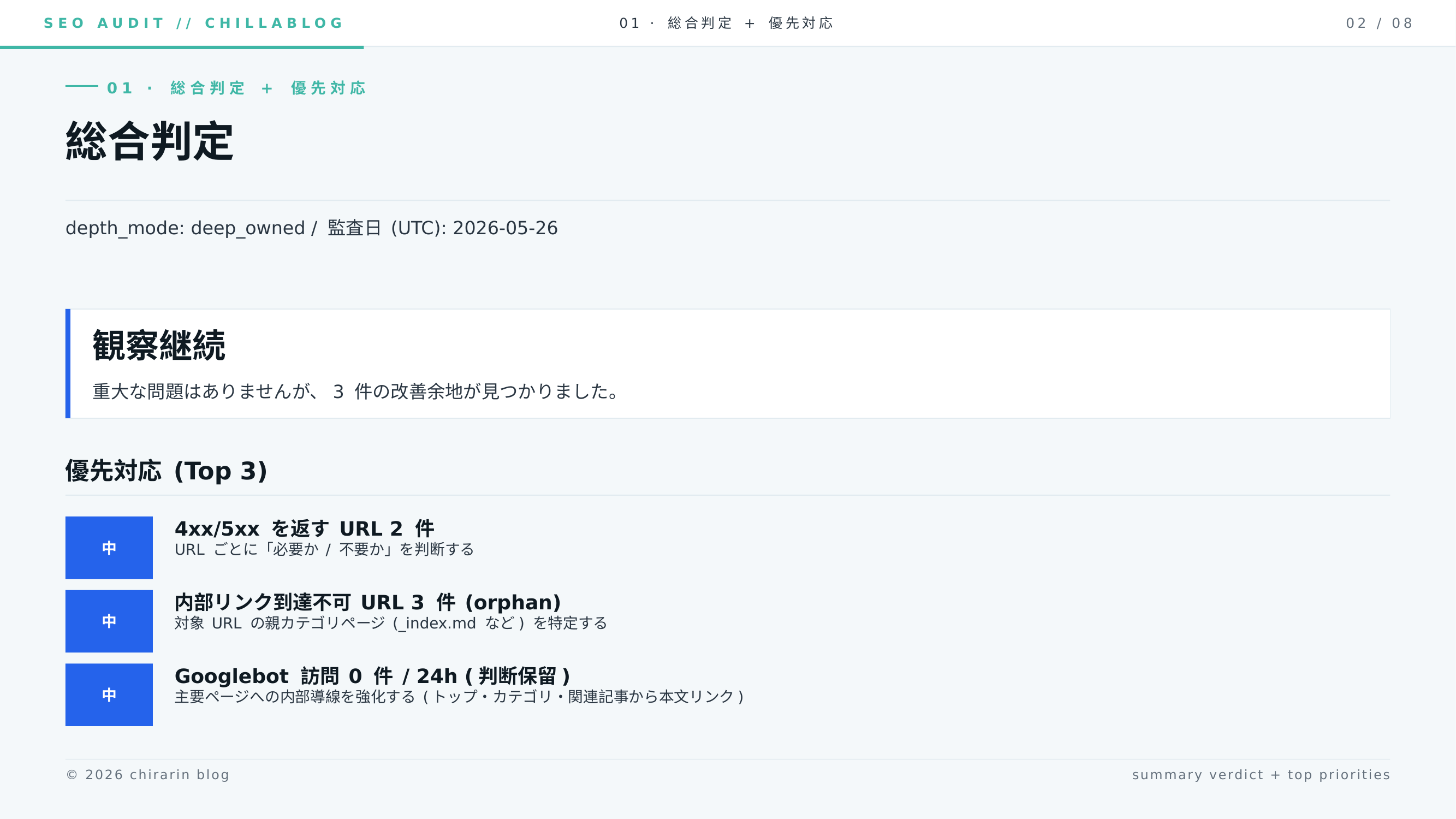
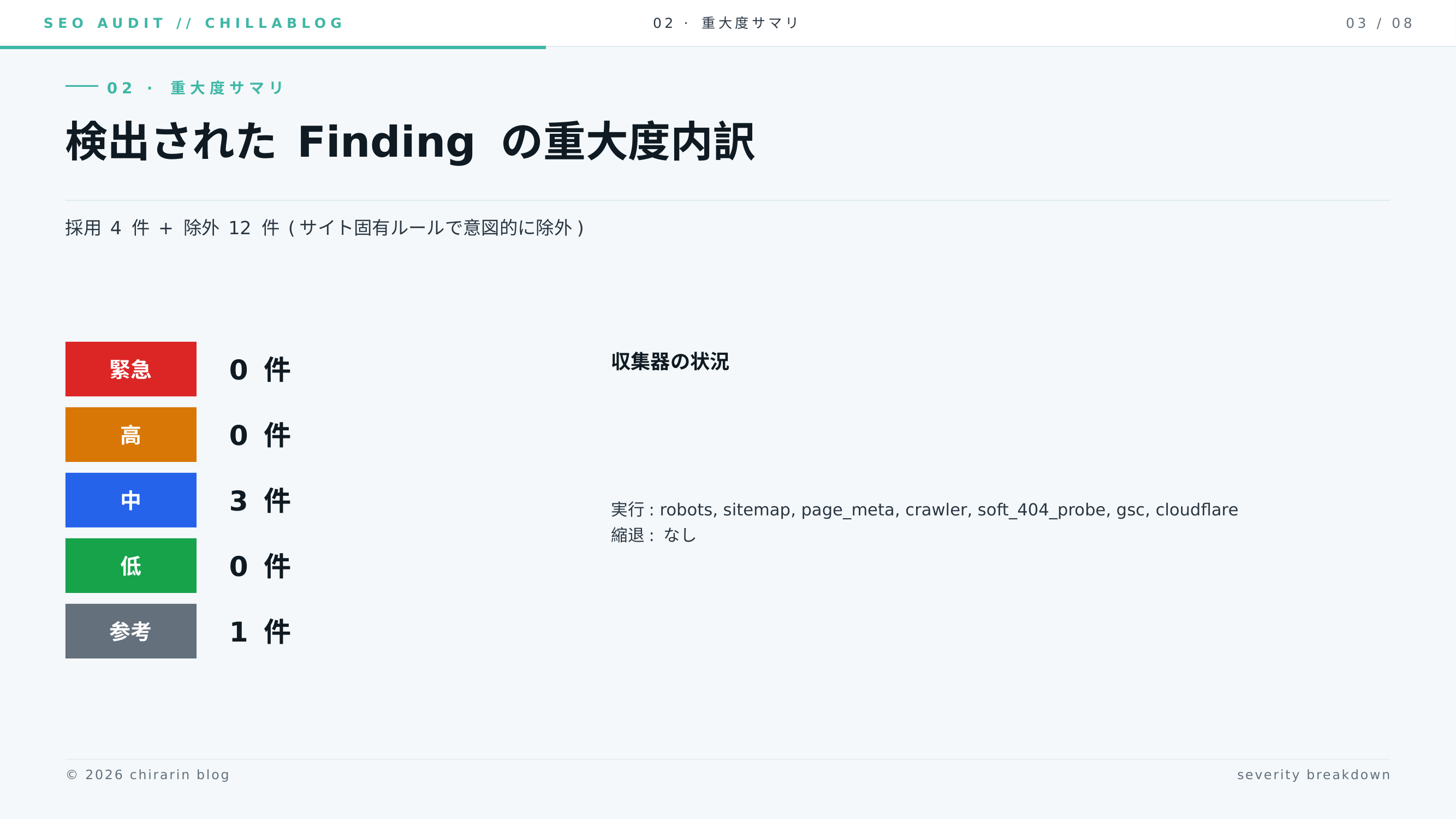
Day 3 (2026-05-26): Finding 4 件、verdict “観察継続”
3 日目はレポートが大幅に整理されたバージョン (Phase 3d) になり、verdict と top_priorities が summary に乗るようになりました。
| 項目 | 値 |
|---|---|
| 採用 Finding | 4 件 (medium 3 / info 1) |
| 除外 Finding | 12 件 |
| クロール総ページ | 208 |
| sitemap 掲載 URL | 330 |
| 総合判定 | 観察継続 |
medium が 3 件揃ったのは、前日と同じ 4xx 2 件 + orphan 3 件に加えて、新しく「Googlebot 訪問 0 件 / 24h (判断保留)」が立ったためです。Cloudflare の 24 時間ログでは 0 件、ただし 7 日 / 30 日のログは収集器未対応のため判断保留、という慎重な書き方になっています。
ここで嬉しかったのは、レポートが「優先対応するトップ 3」を自動で吐き出してくれるようになっていたことです。読みやすい:
- 中: 4xx/5xx を返す URL 2 件 — URL ごとに「必要か / 不要か」を判断する
- 中: 内部リンク到達不可 URL 3 件 (orphan) — 親カテゴリページを特定する
- 中: Googlebot 訪問 0 件 / 24h (判断保留) — 主要ページへの内部導線を強化する
施策依存関係まで添えてくれるので「とりあえずこれだけやれば良い」という最短路がそのまま読めるようになっていました。自分で書いておいて言うのも変ですが、ツールに 1 段格上げされた感がありました。
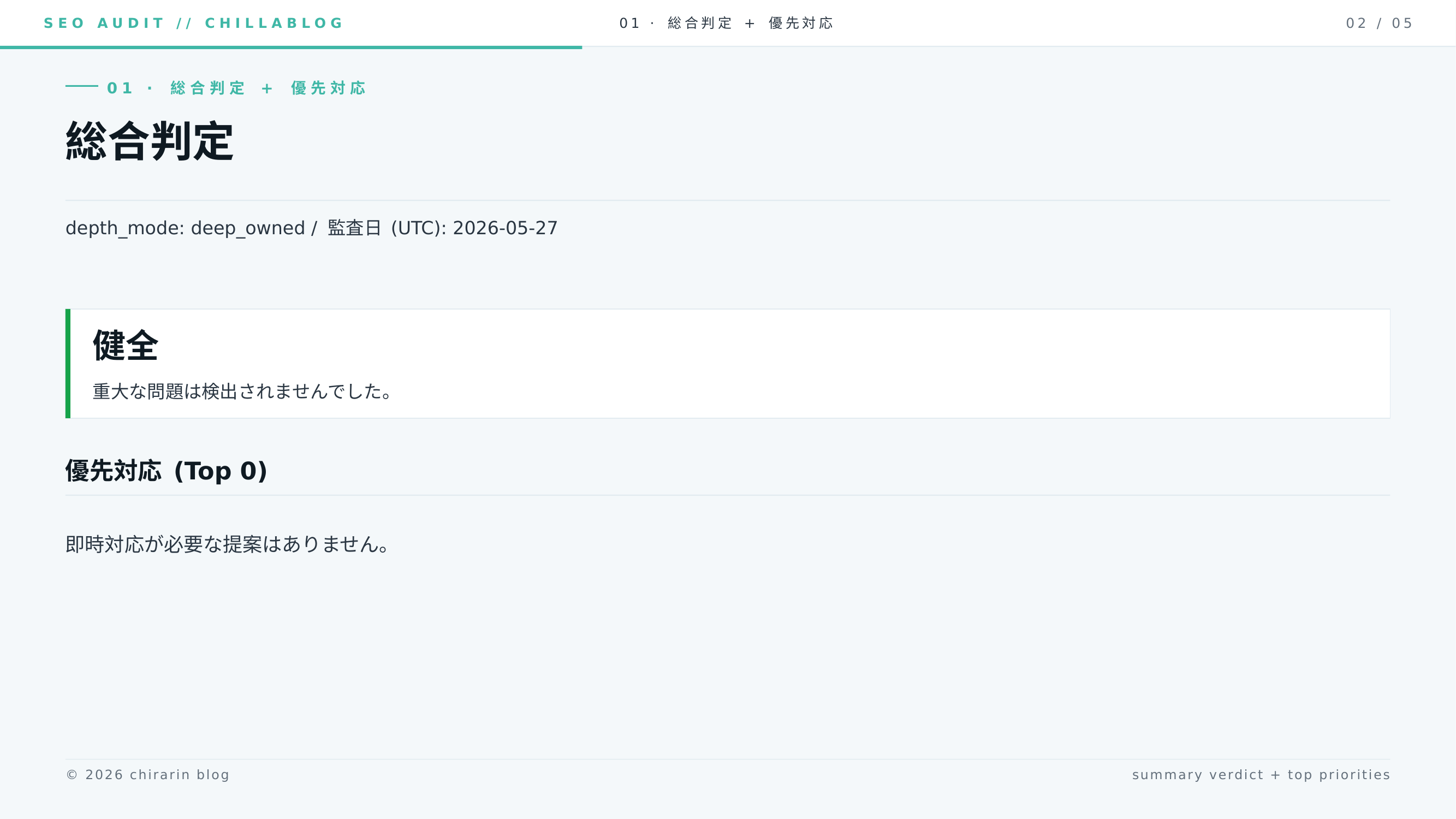
実際に出力されたレポート (PowerPoint 形式) のスライドがこちらです。左右の矢印でめくれます。総合判定の「観察継続」サマリから、4xx/5xx・orphan それぞれの指摘詳細、重大度の内訳までが順に並びます。指摘の各スライドは「問題 / 影響 / 対象 URL / 推奨対応」が 1 枚にまとまる構成です。
link sources は別ファイル (.link_sources.csv / .link_sources.json) に切り出すようになっていて、本文 md はぐっと読みやすくなっています。43 件のリンク元を本文に並べられても困るので、これは正解の分離でした。
Day 4 (2026-05-27): Finding 1 件、verdict “健全”
4 日目で Finding は info 1 件だけになりました。
| 項目 | 値 |
|---|---|
| 採用 Finding | 1 件 (info 1) |
| 除外 Finding | 10 件 |
| クロール総ページ | 183 |
| sitemap 掲載 URL | 305 |
| 総合判定 | 健全 |
3 日目の medium 3 件が消えた理由は、間にちまちま対応した結果です。
- 4xx の
/posts/2026-04-26_brand-tokens-portability/への古い内部リンクは別記事から削除 - orphan の
/categories/life/legal/postsへの本文リンクは、関連する場所に文脈リンク (= 主題語アンカーで本文中に置く) を追加 - email obfuscation の 404 は除外ルールに移行 (Cloudflare 内部経路の挙動でブログ運用上は害がない、と判断)
ツールがちゃんと「直すと消える」「ルール側で flat に持つ判断もある」の両方を表現できているのは想定通りでした。除外側 (domain_state) に書ける項目を増やしたのは、自分のブログで「これは誤検出として残したい」「これは対応済み」を実際に運用しないと、必要な粒度が見えてこなかった部分です。
verdict も monitoring から healthy に上がりました。Cloudflare 24h の Googlebot HTTP request は 6 件、WAF block 0 件。短期の数字としては問題なしです。
同じレポートを Day 3 と並べると違いが分かりやすいです。総合判定が「観察継続」から「健全」に変わり、優先対応のトップ項目が消えています。

4 日分まとめ: Finding 推移と質的観察
| 日付 | 採用 Finding | 内訳 | クロール | sitemap | verdict |
|---|---|---|---|---|---|
| 2026-05-24 | 2 | high 1 / info 1 | 6 | 323 | (verdict 未実装) |
| 2026-05-25 | 3 | medium 2 / info 1 | 209 | 329 | (verdict 未実装) |
| 2026-05-26 | 4 | medium 3 / info 1 | 208 | 330 | 観察継続 |
| 2026-05-27 | 1 | info 1 | 183 | 305 | 健全 |
数字の動き方を読むと、初日の “high 1” は crawler を浅く回したことで「sitemap に載っているのに本文リンクなし」の URL が広めに引っ掛かったもの。2-3 日目で BFS を本格化させると、深い導線を辿れる URL は orphan から外れ、本当に本文導線が無いものだけが残った形です。
sitemap 件数が 4 日間で 323 → 329 → 330 → 305 と微変動しているのは、AI 記事 (週次ニュース系) を sitemap 除外する設定変更 (PR #406) を間に挟んだためで、ここは数字としては正常な減り方です。
GSC URL Inspection は途中で OAuth トークンが切れて 401 を返し続けたので、この期間内の Indexed 数の経時データは取れませんでした。OAuth 再認証はこのあとに別フローで処理し、Indexed 数の継続観察は本記事の続編で別途扱います。今回はクロール側 (sitemap / crawler / Googlebot ログ) の数字に絞っての観察記録です。
自分のブログに当てて分かったこと
数字を並べるだけの記事にしないために、4 日間で気付いたことを 3 つ整理しておきます。
1. 「除外ルールを持てる」のは個人ブログでは決定的に効く
汎用 SEO ツールが返してくる指摘の半分以上は、自分のブログでは「対応済み」または「誤検出」でした。これを毎日ノイズとして眺めるのは精神的に良くありません。
domain_state という YAML を 1 個書いて「PR #372 で description は対応済み」「JSON-LD Article は実装済 / Hugo テンプレでヒューリスティック判定が当たらないだけ」と宣言できるようにしたことで、4 日間のレポート末尾に並ぶ「除外された Finding」は気持ちよく無視できるようになりました。これは個人ブログを継続的に監査する場合の前提条件だと思います。
2. crawler の打ち切り上限はレポートに必ず併記する
1 日目に “orphan 10 件” と出ていたのが、2 日目以降は 3 件に減りました。これは BFS の深さが違うからで、ツール側がレポートに crawled_pages と crawl_truncated_at_max を必ず併記するように設計しておいて本当に助かりました。
「数字が減ったから改善した」のか「クロール深度が違うから見え方が変わっただけ」なのかは、メトリクスを横に置かないと判別できません。SEO 系の数字は、収集条件抜きに読むと簡単に嘘になります。
3. レポートを「優先トップ 3」まで畳んでくれるのは想像以上に効く
Phase 3d で verdict と top_priorities が summary に入った 3 日目以降、レポートを開いて 5 秒で「今日は何をすればよいか」が読めるようになりました。
採用 Finding が 4 件あっても、本当に対応すべき順番と依存関係が 3 行で書いてあるなら、その 3 行だけ見ればいい。それ以外は付録に逃がす、という構造に整理したのは、自分自身が毎日読む人だったからこそ「これは要らない情報だ」「これは見出しに欲しい」が分かったところがあります。
ツールとシリーズの関係
このツールは個人で動かす想定で作っています。SaaS にする予定はなく、自ドメインに当て続ける運用が中心です。OSS 公開の判断は別途検討中で、GitHub に出すかどうかはまだ決めていません。
設計プロセス・実装ノウハウ・除外ルール (domain_state.yaml) の書き方・Claude API の組み込み方は、有料シリーズ SEO チェッカー構築ガイド (¥1,500、7 章) に集約してあります。本記事はあくまで「自分のブログに当てて 4 日見た」事実証跡として置きます。
注: ツールを動かす場合は、対象が自分の所有・運営するサイトであることを必ず確認してください。本人以外が運営するサイトへの監査ツール実行は、本シリーズの想定範囲外です。
次にやること
- GSC OAuth を再認証して、Indexed 数の経時データを再取得する
- 6 週間後 (2026-07 中旬を想定) に再観測して、続編記事として「1 ヶ月半経って何が変わったか」を書く
- Phase 3f 以降の Googlebot 7 日 / 30 日ログ収集器ができたら、判断保留が残らない形で再評価する
- AI コスト・所要時間の実測値は、まだ集計の仕組みを入れていないので、ツール側に計測を入れてから別記事で扱う
ツールの観察記録はこれを単発で終わらせず、四半期に 1 回くらいの頻度で続編を出していく予定です。今回はそのキックオフです。


コメント