監視VMのディスクフル原因4重奏 — Splunk・journald・Prometheus・VFreeを一気に直して NAS 段階退避まで設計し直した話
監視 VM の root FS が 100% に達した日。原因は Splunk retention 未反映 / journald 無制限 / Prometheus 30 日保持 / ubuntu-vg の VFree 放置の 4 つが同時に刺さった複合障害。retention 設計と NAS 段階退避まで再設計した記録です。
はじめに
Splunk が落ちた話だと思って蓋を開けたら、ディスクフルの原因が 4 つ同時に走っていました。
2026 年 4 月 28 日。監視 VM の chillarin-ops(172.16.1.151)で、SigNoz の Zookeeper コンテナが No space left on device で再起動ループに入っていることに気づきました。最初は「Splunk のインデックスがまた育ちすぎたかな」くらいの軽い気持ちで df -h を叩いたのですが、ルート FS が 187G / 195G、Avail 0 でちゃんと振り切れていました。
調べていくと、root FS を圧迫していたのは Splunk だけではありませんでした。
- Splunk の indexes.conf が container に届いていなかった(retention 設定の bind mount 漏れ)
- journald が無制限蓄積していた(
SystemMaxUse未設定) - Prometheus の retention が 30 日のままだった(ホームラボの参照頻度に対して過剰)
ubuntu-vgに VFree 99GB が放置されていた(Ubuntu autoinstall の LVM デフォルトの罠)
どれも単独であれば「あー、retention 直すか」「vacuum-size で削るか」で済みます。今回は 4 つが同時に root FS を食い合っていたので、1 つ直しても次の犯人がすぐ顔を出します。最終的には retention 設計 + LVM 拡張 + NAS 段階退避まで一気に作り直しました。本記事はその全記録です。
Proxmox 複合障害(e1000e + NFS + 監視ギャップ)の記事と並ぶ、自宅サーバ複合障害シリーズ第 2 弾にあたります。
発端: SigNoz Zookeeper の再起動ループから始まった
第一報は SigNoz 側からでした。docker ps を眺めると Zookeeper が Restarting (1) を繰り返しています。ログを見るとあっさり原因が出ます。
Failed to create log file /datalog/version-2/log.... : No space left on deviceボリュームのマウント先を見ると Docker のデータディレクトリ。root FS の話です。df -h で確認します。
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/ubuntu--vg-ubuntu--lv 195G 187G 0 100% /100% です。df の表示が Avail 0 まで振り切れている時点で、コンテナだけの問題ではないと察します。du -h --max-depth=1 /var/lib/docker/volumes/ | sort -h | tail で大きなボリュームを見ると、トップは obs-lab_splunk-data の 163GB。これは知っている形です。Splunk のインデックスが retention 設定なしで蓄積するとこうなります。
ところがここから話がまっすぐ進まない。私はちゃんと ~/obs-lab/splunk/etc/system/local/indexes.conf に retention を書いていたはずなのです。Splunk 再起動どころか、Splunk container 自体を一度全部止めて再起動しているのに、3 ヶ月ぶんのインデックスがそのまま残っている。「設定が読まれていない」という嫌な仮説が立ちました。
一次対応の制約: full FS では growpart も resize2fs も死ぬ罠
「retention 直すか」と動く前に、まず root FS を 0% から引き剥がさないと作業すらできません。これは経験的にいつも詰むパターンで、ちょっとだけ書いておきます。
growpart は /tmp に一時パーティションテーブルを書き出します。pvresize も lvextend も内部で何かしら書きます。root FS が 100% だとこれらが全部 No space left on device で死ぬ。先に数 GB だけ空けておかないと、拡張作業に入れません。
私が使うのはこの順番です。
# 1. まずヤバいコンテナを止める(restart loop の連鎖を切る)
docker stop signoz-zookeeper signoz-clickhouse
# 2. 停止状態のコンテナ image を削除して数GB稼ぐ
docker container prune -f
docker image prune -af # dangling だけでなく未参照 image も全削除
# 3. journald も即時 rotate して圧縮
journalctl --vacuum-size=200Mdocker image prune -af で 6.8GB 戻ってきました。これで df -h は Avail 7.2GB 程度に回復。ここから初めて拡張作業に入れます。
Proxmox 側で scsi0 を +200GB
VM 自身のディスクが 195GB で天井に張り付いているので、まずは Proxmox 側でディスクを足します。VM はオンラインのまま。
# pve2 上で実行 (chillarin-ops は VMID 151, nuc2 配置)
qm resize 151 scsi0 +200Gこれで Proxmox 側のディスクは 395GB に。VM 内ではまだ反映されていません。Linux 側で順番に拡張していきます。
# chillarin-ops 上で実行
sudo growpart /dev/sda 3 # GPT パーティション 3 を拡張
sudo pvresize /dev/sda3 # LVM PV のサイズを再認識
sudo lvextend -l +100%FREE /dev/ubuntu-vg/ubuntu-lv
sudo resize2fs /dev/ubuntu-vg/ubuntu-lvgrowpart → pvresize → lvextend → resize2fs の 4 段の順番は LVM on GPT のお決まりです。途中で 1 つでも飛ばすと「拡張したのに df で増えない」が起きるので、毎回この順で打ちます。
これで一旦 root FS が 195GB → 392GB に。Avail が 200GB 戻ったので、ここから腰を据えて原因 4 つを潰しにいけます。
原因 1: Splunk indexes.conf が container に届いていなかった
最初の本丸は Splunk です。splunk-data が 163GB に膨れていた根本原因を追います。
indexes.conf の中身自体は、ホスト側でちゃんと書かれていました。
# ~/obs-lab/splunk/etc/system/local/indexes.conf
[default]
frozenTimePeriodInSecs = 604800 # 7 日
[nginx]
maxTotalDataSizeMB = 5120
coldToFrozenDir = /mnt/nas/ops-archive/splunk/frozen/nginx
...7 日 retention に絞って、各 index は 5GB を上限にして、冷却された bucket は NAS に退避する設計です。これ自体は正しい。問題はその設定ファイルが container の中に届いていなかった ことでした。
docker compose config で compose の volumes セクションを確認すると、Splunk container の bind mount に etc/system/local/indexes.conf が含まれていません。~/obs-lab/splunk/etc/system/local/ というディレクトリは作っていたのに、compose.yml にマウント定義を書き忘れていた、というだけの話です。
Splunk container は indexes.conf を読みません。読まなければ何が起きるかというと、Splunk のデフォルト値が効きます。frozenTimePeriodInSecs のデフォルトは 188697600 秒 (約 6 年)。3 ヶ月どころか 6 年蓄積する設定で、ホームラボの SSD 上で動いていたわけです。膨らむのは時間の問題でした。
確認方法: btool で実効値を見る
設定が届いているかどうかは Splunk 自身に聞くのが一番早いです。container に入って btool を叩きます。
docker exec -it splunk /opt/splunk/bin/splunk btool indexes list nginx --debug--debug を付けると、各設定値が「どの conf ファイルから来たか」がパス付きで出ます。indexes.conf を読んでいなければ、すべての設定が /opt/splunk/etc/system/default/indexes.conf から来ます。読んでいれば local/indexes.conf が混じってきます。今回は前者でした。「設定書いたのに効かない」時はこのコマンドが効きます。
修正: compose.yml に bind mount を追加
修正は単純で、compose の Splunk セクションに bind mount を 2 行足すだけです。
services:
splunk:
image: splunk/splunk:9.x
volumes:
- splunk-data:/opt/splunk/var
# 以下 2 行を追加
- ./splunk/etc/system/local/indexes.conf:/opt/splunk/etc/system/local/indexes.conf:ro
- /mnt/nas/ops-archive/splunk/frozen:/mnt/nas/ops-archive/splunk/frozen2 つ目の bind mount は NAS の frozen 退避先です。container 内から coldToFrozenDir で指す先がホスト側 NFS マウントと同じパスで見える必要があるので、これも明示的に渡します。docker compose up -d splunk で再起動して、再度 btool で確認したら今度は local/indexes.conf の値が出てきました。
$_index_name 展開の罠
実は最初は indexes.conf の [default] stanza にこう書いていました。
[default]
frozenTimePeriodInSecs = 604800
coldToFrozenDir = /mnt/nas/ops-archive/splunk/frozen/$_index_name$_index_name は Splunk が freeze 時に index 名へ置換してくれる変数です。これで [default] に 1 行書くだけで全 index に効くはずでした。
ところが実機では展開されません。btool indexes list nginx で見ると、coldToFrozenDir が /mnt/nas/ops-archive/splunk/frozen/$_index_name という文字列のまま入ってきます。Splunk は freeze 時にディレクトリ名を解釈できず、freeze 処理が失敗します。
原因はおそらく [default] stanza での変数展開の扱いに version 依存があることなのですが、深追いはやめて per-index stanza に明示展開で書く方針に切り替えました。
[default]
frozenTimePeriodInSecs = 604800
[nginx]
homePath = $SPLUNK_DB/nginx/db
coldPath = $SPLUNK_DB/nginx/colddb
thawedPath = $SPLUNK_DB/nginx/thaweddb
maxTotalDataSizeMB = 5120
coldToFrozenDir = /mnt/nas/ops-archive/splunk/frozen/nginx
[metrics]
homePath = $SPLUNK_DB/metrics/db
coldPath = $SPLUNK_DB/metrics/colddb
thawedPath = $SPLUNK_DB/metrics/thaweddb
maxTotalDataSizeMB = 5120
coldToFrozenDir = /mnt/nas/ops-archive/splunk/frozen/metrics
# syslog / network も同形式「DRY じゃない」が気になる気持ちはありますが、index 数が 4 つなので per-index 明示の方が読みやすく、ハマる原因も減ります。Splunk の $_index_name 展開を信用するより、テンプレで横にコピペした方が運用上ラクでした。
NAS 側の準備
coldToFrozenDir の先である NAS 側のディレクトリは、Splunk container の UID(41812)が書き込める必要があります。NFS export を切って chown します。
# QNAP 側で実行(admin)
mkdir -p /share/CACHEDEV1_DATA/ops-archive/splunk/frozen
chown -R 41812:41812 /share/CACHEDEV1_DATA/ops-archive
chmod 755 /share/CACHEDEV1_DATA/ops-archiveNFS export の側では no_root_squash が必須です。これがないと container 側で root に見えていても UID 41812 として書こうとして弾かれます。export 行はこんな形になります。
/ops-archive 172.16.1.0/24(rw,sync,no_root_squash,no_subtree_check)ここまでやって、docker compose up -d splunk で再起動。docker logs splunk を眺めると、bucket roll のメッセージで Moving bucket ... to frozen がポツポツ出始めました。実機の /mnt/nas/ops-archive/splunk/frozen/<index>/ に bucket ディレクトリが落ちてきます。動いています。
原因 2: journald が無制限だった
Splunk が落ち着いたところで du -h --max-depth=1 /var/log を打つと、/var/log/journal/ が 3.2GB あります。これも片付けます。
/etc/systemd/journald.conf を見ると、ほぼ全項目がコメントアウトでデフォルトのままでした。デフォルト動作の journald は、利用可能な disk space の 10% まで使い、その中で古いものから削るというルールです。「10% まで使う」と聞くと「じゃあ自動で抑えてくれてるんでしょ」と思いがちですが、当時の root FS が 195GB だったので 10% = 19.5GB です。3.2GB はまだ序の口で、放っておけばまだ膨らみます。
ホームラボの監視 VM で「7 日以上前の journald エントリを参照することがあるか」と問うと、答えはほぼ No です。SigNoz と Loki が並走しているので、systemd ジャーナルは「直近 1 週間のトラブルシュート用」と割り切ってよい。
# /etc/systemd/journald.conf
[Journal]
SystemMaxUse=500M
MaxRetentionSec=7daySystemMaxUse=500M で「最大 500MB まで」、MaxRetentionSec=7day で「7 日以上前のものは削る」の二段で縛ります。
設定反映後は即時 rotate したいので、systemd-journald に SIGUSR2 を送ります。これが「今すぐ rotate しろ」のシグナルです。
sudo systemctl kill --kill-who=main -s SIGUSR2 systemd-journald
journalctl --vacuum-size=500M
journalctl --disk-usageこれで 3.2GB → 490MB に縮みました。journald 単独では大した量ではありませんが、4 重奏のうちの 1 本としては効きます。
原因 3: Prometheus retention が 30 日だった
Prometheus は /var/lib/docker/volumes/ops_prometheus-data/_data/data/ で 5.5GB。これも見ます。
compose の Prometheus サービスを見ると、--storage.tsdb.retention.time=30d が指定されていました。30 日。これも考え直す必要があります。
監視 VM のホームラボでの使い方を整理すると、私は基本的に「直近 24 時間〜72 時間」の遡及しかしません。週に 1 度くらい「1 週間前は何時にロード上がってたか」を見ることはあっても、それより古いのは見ません。Grafana の長期トレンドが必要なら、別途集計用のロールアップを持つべきで、TSDB の生データを 30 日抱えるのは違う。
判断としては「ローカル TSDB は 7 日、それより古いものは NAS にスナップショット退避」です。
# compose の prometheus サービス
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--storage.tsdb.retention.time=7d'
- '--web.enable-admin-api' # snapshot API を有効化
- '--web.enable-lifecycle' # 設定リロードを有効化--storage.tsdb.retention.time=7d で 7 日に縮退、--web.enable-admin-api で snapshot API を有効化、--web.enable-lifecycle で /-/reload 経由のリロードを有効化、の 3 セットです。
docker compose up -d prometheus で反映すると、Prometheus が起動時に古いブロックを削り始めます。5.5GB → 2.0GB まで即時に縮みました。
ただ消すと振り返り精度が落ちます。7 日より前を参照したい時のために、後述する「snapshot + rsync で NAS に毎日アーカイブ」が要ります。これが原因 3 の片割れで、設計の話に直結します。
原因 4: ubuntu-vg に VFree 99GB が放置されていた
ここまでで Splunk・journald・Prometheus を絞り、df -h は 392G / 16% まで戻りました。普通ならこれで終わりです。ただせっかく lvdisplay を叩いたついでに、vgdisplay も眺めて気づいてしまった。
--- Volume group ---
VG Name ubuntu-vg
System ID
Format lvm2
...
VG Size <195.00 GiB
Alloc PE / Size 24575 / 95.99 GiB
Free PE / Size 25344 / 99.00 GiBAlloc 95.99 GiB / Free 99.00 GiB。ubuntu-vg の半分が ubuntu-lv に渡されていない。これは Ubuntu Server の autoinstall(22.04 / 24.04 の storage に lvm を選んだ場合のデフォルト)で発生する罠です。
実は今回の qm resize 151 scsi0 +200G で 200GB 足したのは、この VFree 99GB の存在を踏まえていなかったから、というのが恥ずかしながら正解です。先に lvextend -l +100%FREE /dev/ubuntu-vg/ubuntu-lv && resize2fs ... するだけで、Proxmox 側のディスクを触らずに 195GB が手に入ったはずでした。
lvextend 自体は LVM 上では非破壊な操作です。空いている PE を LV に渡すだけで、既存のファイルシステム上のデータには触りません。resize2fs をオンラインで打てば再起動すらいりません。
sudo lvextend -l +100%FREE /dev/ubuntu-vg/ubuntu-lv
sudo resize2fs /dev/ubuntu-vg/ubuntu-lvただし、+100%FREE という構文には「気を抜くと取り返しがつかない」雰囲気があります。再現する場合の注意は別途まとめます。
これを打つと ubuntu-lv が 95.99 GiB → 194.99 GiB に。resize2fs でファイルシステムが追随して、df -h が 195G から 392G に増えます(先の qm resize ぶんと合わせて)。
教訓: autoinstall のデフォルトを盲信しない
Ubuntu Server の autoinstall で storage: layout: lvm を選ぶと、デフォルトでは VG の半分しか LV に割り当てません。これは「将来スナップショットを取る余裕を残しておく」という設計思想で、それ自体は妥当です。問題は 誰もそれを知らずに使う ことで、結果として「ディスクは 200GB にしたはずなのに 100GB しか見えない」が静かに起こります。
storage: セクションで明示的に size: -1 を指定して「VG 全部を LV に割り当てる」と書くこともできます。私はこの記事を書きながら今後の autoinstall yaml を見直す予定です。
設計: NAS 段階退避 (ローカル 7 日 / NAS 730 日)
ここからは「直す」を超えて「次は起きないように設計し直す」の話です。
監視データには 2 種類の参照パターンがあります。短期参照(直近の調査用、低レイテンシ・高頻度) と 長期アーカイブ(数年単位のキャパシティ計画、年に数回参照)。これを 1 つのストレージに同居させようとすると、必ず短期参照のための SSD が圧迫されます。
今回の答えは「ローカル SSD = 7 日 / NAS(QNAP)= 730 日(2 年)」の二段構成です。QNAP には 4.4TB の空きがあり、回転ディスクなのでアクセスは遅いですが、年次参照には十分です。
QNAP に ops-archive 共有を作成
QNAP の管理画面で ops-archive 共有を作成し、NFSv4 で export します。
# /etc/exports.d/ops-archive.conf (QNAP 側)
/share/CACHEDEV1_DATA/ops-archive 172.16.1.0/24(rw,sync,no_root_squash,no_subtree_check)no_root_squash は前述の Splunk UID 41812 書き込みのために必須です。
chillarin-ops 側 fstab でマウント
監視 VM 側では /etc/fstab に NFSv4 マウントを 1 行足します。
192.168.1.251:/ops-archive /mnt/nas/ops-archive nfs4 _netdev,soft,timeo=180,retrans=2 0 0ポイントは _netdev と soft です。
_netdev: ネットワーク到達後にマウントを試みる。これがないと、起動時に NAS が見えていない瞬間に boot が止まりかねないsoft: NFS サーバが応答しなくなった時に、クライアント側の I/O を 失敗として返す。hardだと無限に待つので、NAS が落ちると Splunk container の bucket roll などが固まる
soft は I/O エラーが返るので「データロスが起きるのでは」という指摘もあって、用途次第なのですが、監視 VM の archive 用途(最悪は次の rsync でリトライできる)であれば soft を選ぶ方が現実的です。
なぜ compose driver_opts での NFS 直書きを避けたか
Docker compose では volumes セクションの driver_opts で NFS マウントを直接書くこともできます。
# こうは書かなかった
volumes:
nas-archive:
driver: local
driver_opts:
type: nfs
o: addr=192.168.1.251,nfsvers=4,soft
device: ":/ops-archive"これをやると Docker が container 起動時にマウントしてくれるので、ホスト側の fstab を汚さなくて済みます。が、NAS が落ちた瞬間に Splunk container がマウント不可で起動失敗 になります。Docker volume の NFS は「マウントが成立しないと container 自体が起動しない」性質なので、依存関係が強すぎます。
ホスト側の OS で _netdev,soft マウントしておけば、NAS が落ちても OS は起動するし、container も(マウントが空でも)起動だけはします。後で NAS が戻ったらマウントが復活して書き込みが流れる。「監視 VM が NAS と一蓮托生にならない」 ことを優先しました。
Prometheus snapshot + rsync の毎日バックアップ設計
retention 7 日に縮めた Prometheus を、毎日 NAS にアーカイブする仕組みを書きます。Prometheus の --web.enable-admin-api で /api/v1/admin/tsdb/snapshot が叩けるので、それを使います。
/usr/local/bin/prom-archive.sh
#!/usr/bin/env bash
set -euo pipefail
PROM_URL="http://localhost:9090"
SNAP_SRC="/var/lib/docker/volumes/ops_prometheus-data/_data/data/snapshots"
NAS_DEST="/mnt/nas/ops-archive/prometheus/snapshots"
RETAIN_DAYS=730
MIN_FREE_PCT=10
mountpoint -q /mnt/nas/ops-archive || { echo "ERROR: NAS not mounted"; exit 1; }
USED_PCT=$(df --output=pcent /mnt/nas/ops-archive | tail -1 | tr -d ' %')
[ "$USED_PCT" -gt $((100 - MIN_FREE_PCT)) ] && { echo "ERROR: NAS $USED_PCT% used"; exit 1; }
SNAP_NAME=$(curl -fsS -XPOST "$PROM_URL/api/v1/admin/tsdb/snapshot" | jq -r .data.name)
DATE_DIR=$(date +%F)
LAST=$(ls -1d "$NAS_DEST"/2*/ 2>/dev/null | grep -v "/${DATE_DIR}/$" | sort | tail -1 || true)
LINK_OPT=()
[ -n "$LAST" ] && LINK_OPT=(--link-dest="$LAST")
mkdir -p "$NAS_DEST"
rsync -a "${LINK_OPT[@]}" --remove-source-files "$SNAP_SRC/$SNAP_NAME/" "$NAS_DEST/$DATE_DIR/"
find "$SNAP_SRC/$SNAP_NAME" -depth -type d -empty -delete
find "$NAS_DEST" -maxdepth 1 -type d -name '20*' -mtime +$RETAIN_DAYS -exec rm -rf {} +このスクリプトのポイントを並べます。
mountpoint -qで NAS マウント確認: マウントされていなければ即時失敗。マウントされていないのに気づかず rsync が/mnt/nas/ops-archive/の実体(ローカルの空ディレクトリ)に書き込み続ける、という事故を防ぎます- NAS の空き容量チェック: 90% を超えていたら書かない。これも自衛
rsync --link-dest: 前回のスナップショットへのハードリンクで dedup。Prometheus の TSDB ブロックは追記中の最新ブロック以外は不変なので、ほぼ全部ハードリンクで済みます--remove-source-files: ローカルの snapshot ディレクトリは rsync 完了後に消す。Prometheus は snapshot を放置するので、明示的に掃除しないとローカルが太りますfind ... -mtime +730 -exec rm -rf: NAS 側で 730 日経過した snapshot ディレクトリを削除
/etc/systemd/system/prom-archive.service + .timer
# prom-archive.service
[Unit]
Description=Prometheus snapshot to NAS
After=network-online.target docker.service
Requires=docker.service
[Service]
Type=oneshot
ExecStart=/usr/local/bin/prom-archive.sh# prom-archive.timer
[Unit]
Description=Run prom-archive.sh daily
[Timer]
OnCalendar=*-*-* 03:00:00
Persistent=true
[Install]
WantedBy=timers.targetPersistent=true を入れておくと、VM が停止していて 03:00 を逃した場合に起動後すぐ実行されます。cron ではなく systemd timer を使う理由は journal でログが追いやすいからです。
sudo systemctl enable --now prom-archive.timer
systemctl list-timers prom-archive.timer30 日経って — --link-dest の効き
書き始めて 16 日経った今日(2026-05-15)時点の du -sh 結果がこれです。
$ du -sh /mnt/nas/ops-archive/prometheus/snapshots/
8.3G /mnt/nas/ops-archive/prometheus/snapshots/
$ du -sh --apparent-size /mnt/nas/ops-archive/prometheus/snapshots/
33G /mnt/nas/ops-archive/prometheus/snapshots/apparent-size(ハードリンクを別カウントする見かけサイズ)が 33GB に対し、実体は 8.3GB。dedup が 4 倍効いている計算です。Prometheus TSDB は追記型なので --link-dest との相性が極めて良い。これが普通のログだとここまでは効かないでしょう。
2 年(730 日)ぶん貯めるとどれくらいになるかですが、増分が 1 日 200〜400MB のペースなので、計算上は 300GB 前後で頭打ちになる見込みです。QNAP の 4.4TB なら全然余裕。
なお実機では 04-28 に組み込み、04-30 だけ snapshot が落ちていません。これは別件で systemd timer の試行錯誤中に外していた日です。気づいた時点で「次の日からやり直す」で済ます方針で、抜けがあった日を遡って取り直すことはしていません(古い TSDB が残っていないので物理的に取れない、というのが大きい)。
ここで「30 日推移を Grafana で振り返ろう」と思って Node Exporter Full を開いたら、Time range を Last 30 days にしても 5/8 以前のデータが出てきません。当の Prometheus は retention 7 日にしたので、ローカルからはもう古いデータが消えている。「ローカル 7 日設計」が文字通り効いていて、自分が書いた設計に自分でハマった瞬間でした。
幸い NAS 退避スナップショットが /mnt/nas/ops-archive/prometheus/snapshots/ に 17 日分積み上がっているので、これを別の Prometheus container にマウントして起動すれば 30 日分のクエリが通ります。
# 各日の snapshot に入っているブロック (ULID dir) を 1 つの dir に集約
# (snapshot 間で重複するブロックは先勝ち)
mkdir -p /tmp/prom-restore/data
for d in /mnt/nas/ops-archive/prometheus/snapshots/2026-*; do
for blk in "$d"/*; do
bname=$(basename "$blk")
[ -e "/tmp/prom-restore/data/$bname" ] || cp -r "$blk" /tmp/prom-restore/data/
done
done
# 空の prometheus.yml を作って、別ポートで読み込み専用 Prometheus を起動
cat > /tmp/prom-restore/prometheus.yml <<EOF
global:
scrape_interval: 60s
EOF
docker run -d --name prom-restore \
--network ops_default \
-p 9095:9090 \
-u $(id -u):$(id -g) \
-v /tmp/prom-restore/data:/prometheus \
-v /tmp/prom-restore/prometheus.yml:/etc/prometheus/prometheus.yml:ro \
prom/prometheus:latest \
--config.file=/etc/prometheus/prometheus.yml \
--storage.tsdb.path=/prometheus \
--storage.tsdb.retention.time=90dあとは Grafana に Prometheus-Restore-30d という datasource を一時的に追加して、Node Exporter Full ダッシュボードでデータソースを切り替えるだけ。出てきたのがこれです。
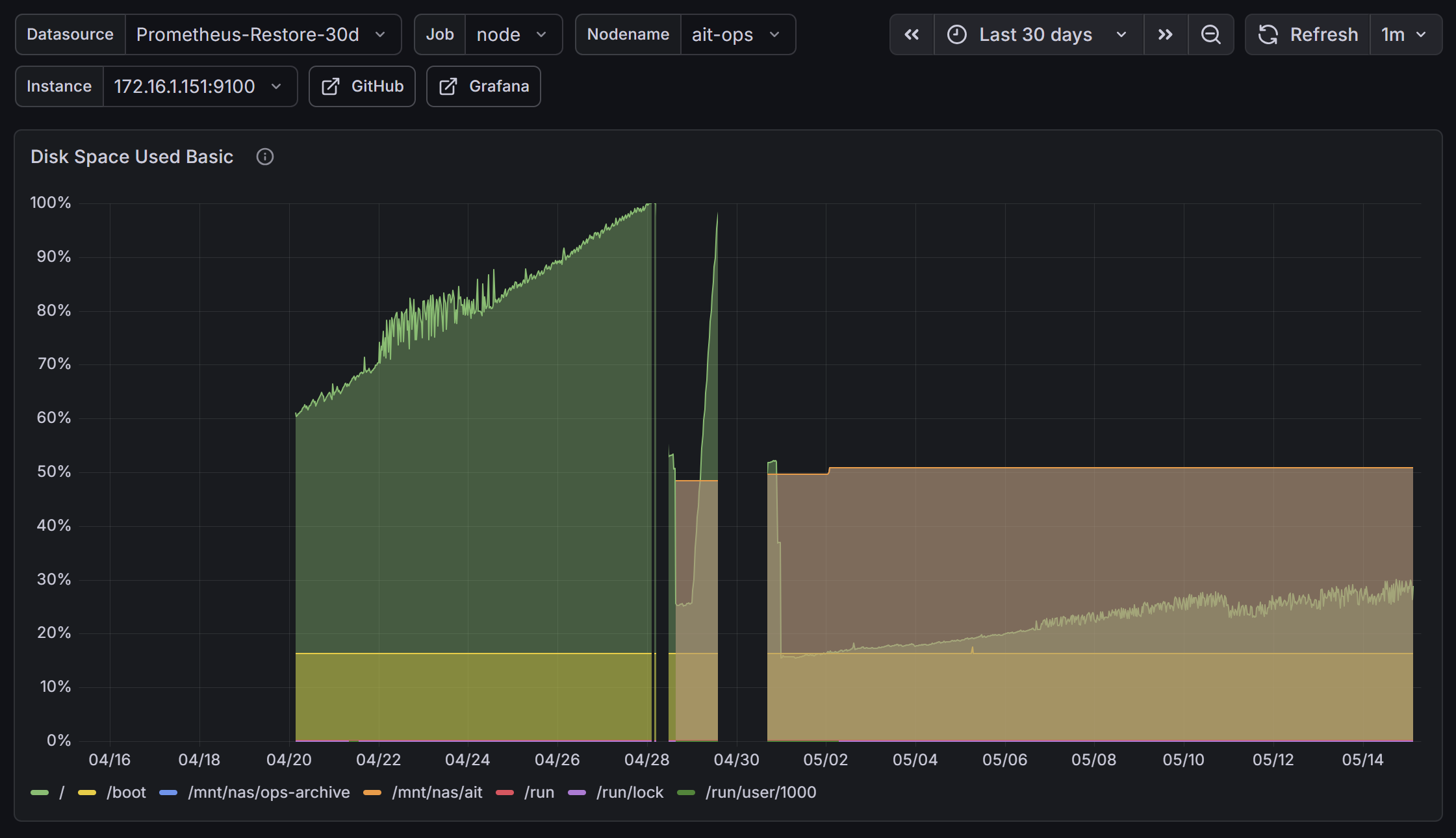
読み方を順に追うと:
- 04-16〜04-19: まだ静かな時期。
/が 60% 前後で安定 - 04-20〜04-28: 緑の
/ラインがじわじわ 60% → 90%+ に直線で伸びていく。これが Splunk indexes.conf 不発でsplunk-dataボリュームが無制限蓄積していた期間 - 04-28: 100% に張り付いた瞬間がディスクフル発生。SigNoz Zookeeper が再起動ループを始めて気づいた日
- 04-28 直後の急落: 一次対応 (停止コンテナの image を
docker image prune) + Splunk retention 反映 + journaldSystemMaxUse=500M+ Prometheus retention=7d を一気に入れた直後の効果。50% 帯まで落ちる - 04-30 の二度目の spike: LVM 拡張中に書き込みが詰まった一瞬。
growpart → pvresize → lvextend → resize2fsのどこかで/が再び 100% を舐めた - 04-30 以降: 30% 帯で安定。これは LVM 拡張で root FS の 分母 が 195GB → 392GB に倍増した結果。データ量がほぼ同じでも見かけ使用率は半分になる
- 05-01 以降: 茶色の
/mnt/nas/ops-archive(NAS 退避先) が 40% → 50% 弱までゆるく右肩上がり。Prometheus snapshot が 1 日 1 回ずつ積まれていく姿
Prometheus TSDB そのものは 5.5GB → 2.0GB にすっと落ちて、それ以降ずっと 2GB 帯で頭打ちになっています。NAS の ops-archive 使用量だけがじわじわ上がる形で、まさに「ローカルは短く、長期は NAS に逃がす」設計が数字に出ています。
ついでに、この「サイドカー Prometheus を NAS スナップショットから一時的に建てる」のはリストア手順そのものでもあります。本番 Prometheus を一度も止めずに、別ポートで別 container を立ち上げて Grafana に datasource を追加するだけで、過去 N 日分のデータが普通にクエリできる状態に戻せる。リストアのしやすさを別途設計する必要がなく、退避設計の素直な副作用として手に入りました。撮影後は docker rm -f prom-restore、Grafana datasource を 1 つ削除、/tmp/prom-restore を rm -rf で完全な原状復帰です。
Alertmanager: 二度と気づかないでは済まさない監視を入れる
ここまでの対策を入れても、結局「root FS が 100% に達するまで気づかなかった」のは監視側の負けです。Alertmanager に容量 alert を 2 段で入れます。
# alert_rules.yml
- alert: DiskUsageHigh
expr: |
(1 - (node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"})) * 100 > 80
for: 10m
labels:
severity: warning
annotations:
summary: "Disk usage > 80% on {{ $labels.instance }} ({{ $labels.mountpoint }})"
- alert: DiskUsageCritical
expr: |
(1 - (node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"})) * 100 > 90
for: 5m
labels:
severity: critical
annotations:
summary: "Disk usage > 90% on {{ $labels.instance }} ({{ $labels.mountpoint }})"80%/10m は「気づき」、90%/5m は「即時行動」の閾値です。for: 10m は瞬間的なバーストで誤発火しないための窓。90% まで上がった時点でもう Splunk バケットロールが間に合わないことが多いので、80% の warning で動くのが本筋です。
predict_linear で予測アラートにする選択肢
もっと攻めるなら、predict_linear で「現在の増加ペースが続けば N 時間後に 90% を超える」という予測アラートを書けます。
- alert: DiskWillFillIn24h
expr: |
predict_linear(node_filesystem_avail_bytes{mountpoint="/"}[6h], 24*3600) < 0
for: 30m
labels:
severity: warning「直近 6 時間の傾きから 24 時間後を予測して、available が負になりそうならアラート」です。私はまだここまでは入れていません。今の retention 設計だと「ゆっくり増えて自然減衰」のサイクルになっているので、predict_linear を入れても誤発火が増える方が先かなと様子見中です。
4 重奏のまとめ
今回入れた対策を 1 枚にまとめます。
| 原因 | 場所 | 対応 | 効果 |
|---|---|---|---|
| Splunk indexes.conf 未反映 | ~/obs-lab/docker-compose.yml | bind mount 追加 + per-index coldToFrozenDir | 163GB の蓄積を 7 日 retention に矯正、bucket roll で NAS 退避 |
| journald 無制限 | /etc/systemd/journald.conf | SystemMaxUse=500M / MaxRetentionSec=7day | 3.2GB → 490MB |
| Prometheus retention 30 日 | ~/ops/docker-compose.yml | --storage.tsdb.retention.time=7d + snapshot/rsync | 5.5GB → 2.0GB、NAS に 730 日アーカイブ |
| ubuntu-vg VFree 99GB | /dev/ubuntu-vg/ubuntu-lv | lvextend -l +100%FREE && resize2fs | root FS 97GB → 195GB(無料で 100GB 追加) |
| 監視ギャップ | Prometheus alert_rules.yml | DiskUsageHigh(80%/10m) + DiskUsageCritical(90%/5m) | 80% 到達で warning、90% で critical |
| アーカイブ層欠落 | QNAP /share/CACHEDEV1_DATA/ops-archive | NFSv4 export + fstab + prom-archive.timer | ローカル 7 日 / NAS 730 日の二段構成 |
現状(2026-05-15)の df -h / は 392G / 27% (101G used)。NAS rotation は 16 日分のスナップショットが apparent 33GB、実体 8.3GB。すべて運用中です。
教訓: 監視 VM 自身の監視ギャップは「複合障害」になりやすい
調査を通じて残った気づきを並べます。
- 「default のままが一番危ない」が連続する。Splunk の
frozenTimePeriodInSecs(6 年)、journald のSystemMaxUse(10%)、Ubuntu autoinstall の LVM (VG 半分)。どれも「default は穏当ですよ」という顔で書かれていながら、組み合わせると root FS を確実に圧迫します。新しいプロダクトを入れる時、retention 系のデフォルトは必ず見る ようにします。 - 「設定書いた」と「設定が効いている」は別。indexes.conf を書いたつもりで効いていなかった今回の罠は、
btool ... --debugのような「実効値を聞く」コマンドを持っていれば防げました。Prometheus にもpromtoolがあり、journald にもsystemd-analyze cat-configがあります。「効いているかを確認する手段」を最初にメモする。 - bind mount 漏れは設定ファイルが綺麗な時ほど見逃す。indexes.conf 自体は完璧に書かれていたので、
grepでファイルを確認すると「ちゃんとある」になる。compose の volumes 定義の差分を見ない限り発覚しません。 - VFree は静かに 100GB を消す。
vgdisplayは普段見ないコマンドですが、Ubuntu Server を使うなら「インストール直後に 1 回叩いて、Free PE が 0 でなければ即lvextend」のクセを付けると一生詰まないと思います。 - 段階退避は最初から設計する。retention 短縮はデータを失うことなので、「短くするだけ」だと意思決定が重くなります。「短期はローカル / 長期は NAS」の二段にすると、ローカルを 7 日に絞ることへの心理的抵抗が消えます。これは Proxmox 複合障害の記事 で書いた「dead-man switch をセットで作る」と同じ筋の話で、監視層を信頼するには「監視データの永続化」も含めて設計する 必要があります。
- 複合障害は単独原因より時間がかかる。今回も Splunk だけなら 1 時間で済んだはずですが、4 つ重なると「1 つ直しても次の犯人が顔を出す」のでまる 2 日かかりました。普段から retention 設計を入れておく方が、ディスクフルが起きた日に retention 設計するより圧倒的にラクです。
複合障害は今後も来ます。S-18 の Proxmox e1000e + NFS + 監視ギャップに続いて、これが 2 回目です。ホームラボ規模でも「インフラ系の複合障害は仕組みが噛み合わなくなるところから起きる」 という形は変わりませんでした。先回りで仕組みを整える方が、起きてから対症療法するより常に安いです。
おわりに
監視 VM が落ちている時は監視も落ちます。だからこそ、監視 VM 自身の容量設計はインフラ全体の信頼性に直結します。今回の 4 重奏は、その当たり前を改めて思い知らされた事案でした。
本記事で書いた retention 設計と NAS 段階退避の構成は、自宅サーバ構築シリーズの一環として無料公開しています。
- 関連記事: VMが起動しない日の話 — Proxmox 複合障害 (複合障害シリーズ第 1 弾)
- シリーズ一覧: 自宅サーバ構築シリーズ
有料コンテンツ案内
本記事で触れた構成の実ファイル一式は、有料コンテンツ「自宅サーバ構築シリーズ」で提供しています。
~/obs-lab/docker-compose.yml(Splunk bind mount を含む全量)~/obs-lab/splunk/etc/system/local/indexes.conf(4 index 分の per-index stanza)~/ops/docker-compose.yml(Prometheus retention + admin API)/usr/local/bin/prom-archive.sh本番スクリプトprom-archive.service/prom-archive.timerの systemd unit- QNAP 側の NFS export 設定
/etc/fstabの NAS マウント行- Alertmanager
alert_rules.ymlの disk usage セクション journald.confの差分パッチ- 本件で使った
btool/lvextend/growpart/pvresizeの調査コマンド集
興味があれば 有料コンテンツ案内ページ をご覧ください。
自宅サーバとネットワークの観測の全体像は 自宅 Observability の完全ガイド — Prometheus + Grafana + Loki で家のサーバとネットワークを観測し続ける にまとめています。監視基盤の設計判断から複合障害・retention 運用までを 1 ページで通読できる Pillar ガイドです。
コメント