家のWAN回線がぽろぽろ落ちる原因を Prometheus + Grafana で見える化した
TDR が使えない C1111 で、SNMP と時系列データから物理層の不調を追う
はじめに
自宅のインターネットがたまに切れます。仕事中に Zoom が落ちることもあれば、ゲーム中にラグが入ることもある。最初は気のせいかと思っていたのですが、Cisco C1111 のログを見たら WAN 側のリンクが物理的に落ちて復旧する を繰り返していました。
ルータも置き換えられない、回線契約も変えられない、ケーブルも宅内設備の途中にある JJ コネクタ で繋がっている状態。手の届く範囲が極端に狭い中で、まず「いつ、どれくらいの頻度で、どんなパターンで落ちているのか」を見える化することにしました。
本記事はその監視構築と、14 日間集めたデータをどう解釈したか、そして次にどんな物理交換を試すかまでの記録です。結論から言うと、データはまだ十分ではなく、原因は「ランダム性のある物理接触不良」という仮説のまま、物理層への介入フェーズに入ります。 続編は物理交換後にあらためて書きます。
背景: マンション備え付け回線という制約
私の住まいはマンションタイプの備え付けインターネット回線です。回線種別もプロバイダも、契約上は自分で変更できません。宅内に光コンセントが来ていて、そこから ONU、Cisco C1111-8P の WAN ポート (Gi0/0/0) に LAN ケーブルで繋いでいる構成です。
ある日、ONU と C1111 の間のケーブル経路をよく見たら、壁内配線と宅内配線の境目で JJ (Jack-to-Jack) コネクタ が挟まっていました。JJ はメスメスの中継コネクタで、規格上は永続配線 (Permanent Link) 側で使うものです。Patch ケーブル区間に挟むことは推奨されていませんが、なぜか挟まっている。しかも壁内側のケーブルカテゴリが不明で、宅内側と混在している疑いがあります。
物件オーナーの設備が一部入っているため、勝手に剥がせない構造です。やれることは限られています。
症状の現れ方
- Zoom や WebRTC 系の通信が突然切れる
- ゲームの ping が一時的に飛ぶ (タイムアウトに近い揺れ)
- C1111 のシステムログに
%LINK-3-UPDOWNと%LINEPROTO-5-UPDOWNが GigabitEthernet0/0/0 で交互に記録される - ケーブルを一度抜いて挿し直すと、しばらく安定する
物理層っぽい振る舞いです。ただ、頻度が高くないので「気のせいかも」と思える境界線にいて、本格的に追いかけるトリガーがなかなか引けない、というのが厄介でした。
一次調査: show interfaces のカウンタを読む
まずやることは、C1111 にログインして show interfaces GigabitEthernet0/0/0 を 1 回叩くことです。瞬間値ではなく、起動からの累積カウンタが見えます。
2026-04-22 時点で取った主要カウンタは以下でした。
Chirarin_RT#show interfaces GigabitEthernet0/0/0
GigabitEthernet0/0/0 is up, line protocol is up
Hardware is ISR4321-2x1GE
...
5 minute input rate 2403000 bits/sec, 313 packets/sec
5 minute output rate 1484000 bits/sec, 166 packets/sec
reliability 255/255, txload 1/255, rxload 1/255
0 runts, 775 giants, 0 throttles
3008 input errors, 3007 CRC, 0 frame, 0 overrun, 0 ignored
0 output errors, 0 collisions, 1 interface resets
115 lost carrier, 0 no carrier, 0 pause outputこのうち、原因切り分けで重要なのは次の三つです。
| カウンタ | 値 | 意味 |
|---|---|---|
lost carrier | 115 | 物理リンクが消失した回数。L1 障害の直接の証拠 |
CRC | 3007 | フレームのチェックサムエラー。L2 の信号品質が悪い時に増える |
giants | 775 | 規格サイズを超えるフレーム。これも信号歪みや MTU 不整合で出る |
lost carrier がカウントされている時点で、物理層でリンクが落ちている事実は確定です。あとはどれくらいの頻度か、どんなタイミングか、です。
19 日後の 2026-05-11 に同じコマンドを叩くと、差分はこうなりました。
| カウンタ | 04-22 | 05-11 | 差分 (19 日間) | 1 日平均 |
|---|---|---|---|---|
lost carrier | 115 | 132 | +17 | 約 0.89 回/日 |
CRC | 3007 | 3185 | +178 | 約 9.4 回/日 |
giants | 775 | 836 | +61 | 約 3.2 回/日 |
interface resets | 1 | 1 | 0 | - |
lost carrier は 約 1 日に 1 回弱のペースで増えている。CRC は 1 日 10 回弱。reliability は 255/255 のまま満点表示ですが、これは累積に対する移動平均なので、低頻度の障害はカウンタが増えていても表に出てきません。
TDR が使えなかった話
物理層が怪しいなら、ケーブル診断機能の TDR (Time Domain Reflectometry) を試したくなります。Cisco IOS には test cable-diagnostics tdr interface <intf> というコマンドがあって、ケーブルのオープン/ショート/長さを反射で測ってくれる、はずでした。
C1111-8P の Gi0/0/0 で叩いてみた結果がこれです。
Chirarin_RT#test cable-diagnostics tdr interface GigabitEthernet0/0/0
% TDR test is not supported on this interfaceLAN 側の Gi0/1/0〜Gi0/1/7 (内蔵スイッチポート) では TDR が動くのに、WAN 側だけ非対応です。理由を調べると、C1111 の WAN ポートは内蔵スイッチエンジン経由ではなく、ルーター側のフォワーディングプレーンに直結している設計でした。TDR は Catalyst 系のスイッチ ASIC に乗っている診断機能なので、ルータ側ポートにはその回路が入っていません。
つまり、C1111 の WAN は 物理層を IOS から覗くインターフェースがほぼ存在しない。手元で取れるのは SNMP の if カウンタと、syslog の UPDOWN メッセージくらい。
この時点で方針が決まりました。TDR で物理を一発診断する道は閉ざされたので、SNMP で時系列パターンを取って原因を絞り込む。
監視を組む: snmp_exporter + Prometheus + Grafana
自宅にはすでに監視 VM (chillarin-ops, 172.16.1.151) があり、Prometheus と Grafana が動いています。ここに snmp_exporter を足して、C1111 から SNMP v2c でメトリクスを引き抜く構成にしました。
全体構成
| コンポーネント | 配置 | 役割 |
|---|---|---|
| snmp_exporter | chillarin-ops 上の Docker | SNMP walk して Prometheus 形式に変換 |
| Prometheus | chillarin-ops | snmp_exporter を 30 秒間隔で scrape |
| Grafana | chillarin-ops | ダッシュボードと state-timeline 可視化 |
| Cisco C1111-8P | 10.1.1.254 | SNMP エージェント (v2c, community: chillarin-com) |
SNMP v2c を使っているのは家庭内の閉じたネットワークだからで、外に出すなら v3 にすべきです。
snmp.yml の罠: metrics: 欠落で series が 0 になる
snmp_exporter は snmp.yml という設定ファイルで walk する OID と、Prometheus メトリクスとして公開する OID を別々に書きます。これを最初混同して、walk セクションだけ書いて起動したら、scrape は成功するのに メトリクスが 0 件 という状態になりました。
# これだと walk はするけど Prometheus には何も出てこない
modules:
if_mib:
walk:
- 1.3.6.1.2.1.2.2
- 1.3.6.1.2.1.31.1.1metrics: セクションを書かないと、exporter は OID ツリーを歩くだけで値を返してくれません。正しい書き方は以下です。
modules:
if_mib:
walk:
- 1.3.6.1.2.1.1
- 1.3.6.1.2.1.2.2
- 1.3.6.1.2.1.31.1.1
metrics:
- name: ifNumber
oid: 1.3.6.1.2.1.2.1
type: gauge
- name: ifIndex
oid: 1.3.6.1.2.1.2.2.1.1
type: gauge
indexes:
- labelname: ifIndex
type: gauge
- name: ifDescr
oid: 1.3.6.1.2.1.2.2.1.2
type: DisplayString
indexes:
- labelname: ifIndex
type: gauge
- name: ifOperStatus
oid: 1.3.6.1.2.1.2.2.1.8
type: gauge
indexes:
- labelname: ifIndex
type: gauge
- name: ifInErrors
oid: 1.3.6.1.2.1.2.2.1.14
type: counter
indexes:
- labelname: ifIndex
type: gauge
# ... ifOutErrors / ifHCInOctets / ifHCOutOctets / ifAlias / ifName など全 14 メトリクス特に 1.3.6.1.2.1.2.2.1.8 = ifOperStatus が今回の主役です。値は 1=up, 2=down で、これの変化回数を Prometheus の changes() 関数で数えれば flap が見えます。
この metrics: 欠落でハマったのは半日くらいで、原因に気付くまで「Prometheus 側の relabel が悪いのか」「community 文字列が違うのか」と無関係な場所を疑いました。教訓は、snmpwalk -v2c -c <community> <ip> 1.3.6.1.2.1.2.2.1.8 を直接叩いて値が返ってくるか先に確認すること。コマンドラインで返ってくるのに Prometheus で見えないなら、snmp_exporter 側の問題です。
prometheus.yml の job 定義
snmp_exporter は /snmp?target=<ip>&module=<module> というクエリで動くタイプなので、Prometheus 側で relabel して target を渡します。
scrape_configs:
- job_name: snmp_network
scrape_interval: 30s
static_configs:
- targets:
- 10.1.1.254 # Chirarin_RT (Cisco C1111)
metrics_path: /snmp
params:
module: [if_mib]
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: snmp-exporter:9116scrape_interval: 30s で十分です。WAN flap は典型的に数秒〜数十秒のダウンで戻ってくるので、30 秒の解像度で取り逃す可能性はありますが、changes() 関数は up→down→up のシーケンスを「変化 2 回」と数えるので、サイクルの両端さえ拾えれば検知できます。
Alert ルール: flap を即時警告にする
alert_rules.yml には三段構えのルールを書きました。
groups:
- name: wan_link
rules:
- alert: WANLinkDown
expr: ifOperStatus{instance="10.1.1.254",ifName="Gi0/0/0"} == 2
for: 30s
labels:
severity: critical
annotations:
summary: "WAN link is DOWN (Gi0/0/0)"
- alert: WANLinkFlapping
expr: changes(ifOperStatus{instance="10.1.1.254",ifName="Gi0/0/0"}[30m]) >= 4
for: 1m
labels:
severity: warning
annotations:
summary: "WAN link flapping detected (>=4 changes in 30m)"
- alert: WANInputErrorsIncreasing
expr: rate(ifInErrors{instance="10.1.1.254",ifName="Gi0/0/0"}[10m]) > 0
for: 10m
labels:
severity: warning
annotations:
summary: "WAN input errors are increasing"changes(ifOperStatus[30m]) >= 4 の意味は、「30 分以内に up/down が 4 回以上変化したら flapping とみなす」。down→up→down→up で 3 回、もう 1 回変化したら 4 回です。瞬断 1 回では発火しないけれど、短時間に何度も落ちる時はすぐ気付ける、というバランスにしました。
WANInputErrorsIncreasing は CRC や input error が増え続けている状態を検知します。これは flap が起きていなくても、信号品質の悪化を早期に拾うためのものです。
Grafana ダッシュボード
ダッシュボードは 10 パネル構成にしました (URL: http://172.16.1.151:3000/d/wan-link-monitoring/)。
| # | パネル | データソース | 目的 |
|---|---|---|---|
| 1 | state-timeline (ifOperStatus) | ifOperStatus | up/down を時系列の帯で見る |
| 2 | flap ヒートマップ | changes(ifOperStatus[1h]) | 曜日 × 時間帯で発生密度を見る |
| 3 | 現在の oper status (stat) | ifOperStatus | いま up なのか down なのか |
| 4 | ifInErrors レート | rate(ifInErrors[5m]) | エラー増加トレンド |
| 5 | ifHCInOctets / ifHCOutOctets | rate(ifHCInOctets[5m]) | 帯域使用率 |
| 6 | ifSpeed | ifSpeed | リンクスピード (1000Mbps 想定) |
| 7 | giants / CRC 累積 | ifInErrors / ifInDiscards | エラー総量の遷移 |
| 8 | ifLastChange | ifLastChange | 最後にステータスが変わった時刻 |
| 9 | ifAlias テーブル | ifAlias | インターフェース説明文 |
| 10 | last 24h サマリー | 各種集計 | flap 数 / ダウン総時間など |
特に重要なのは 1 番の state-timeline と 2 番のヒートマップです。state-timeline はパッと見で「あ、この時間帯に細い赤い線が入った」と分かるので、家族から「ネット切れた」と言われた時に該当時刻を即座に確認できます。
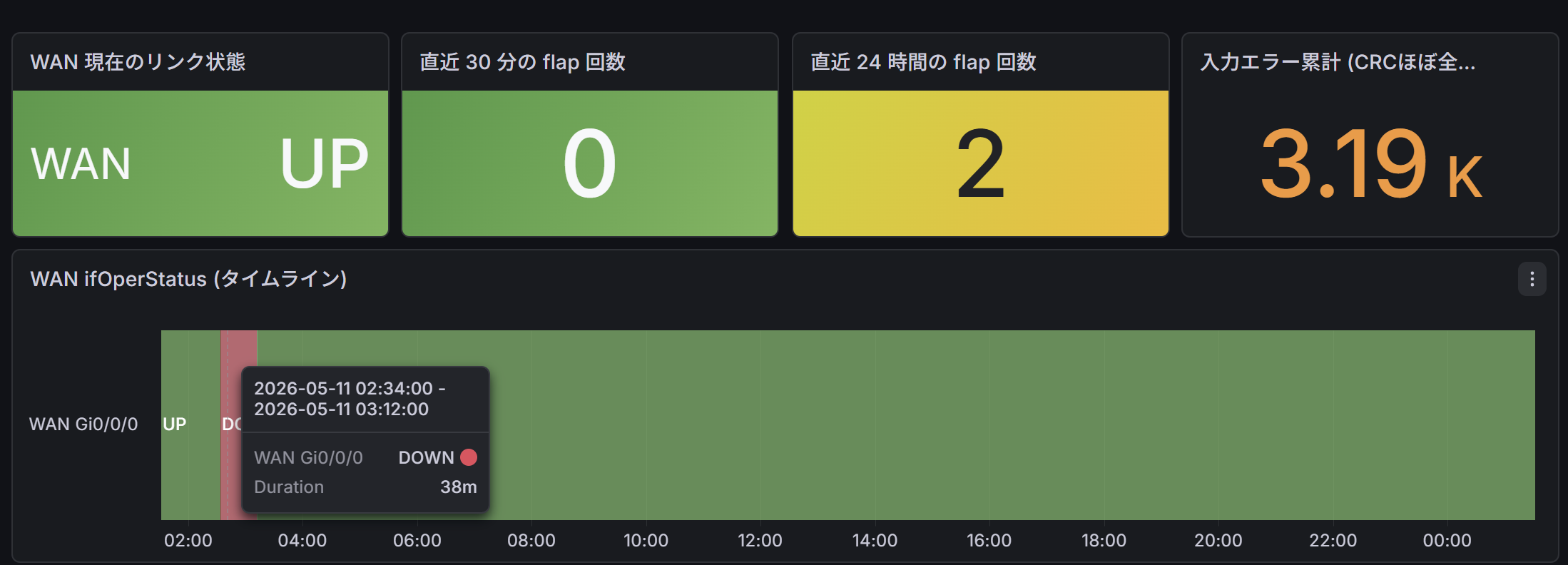
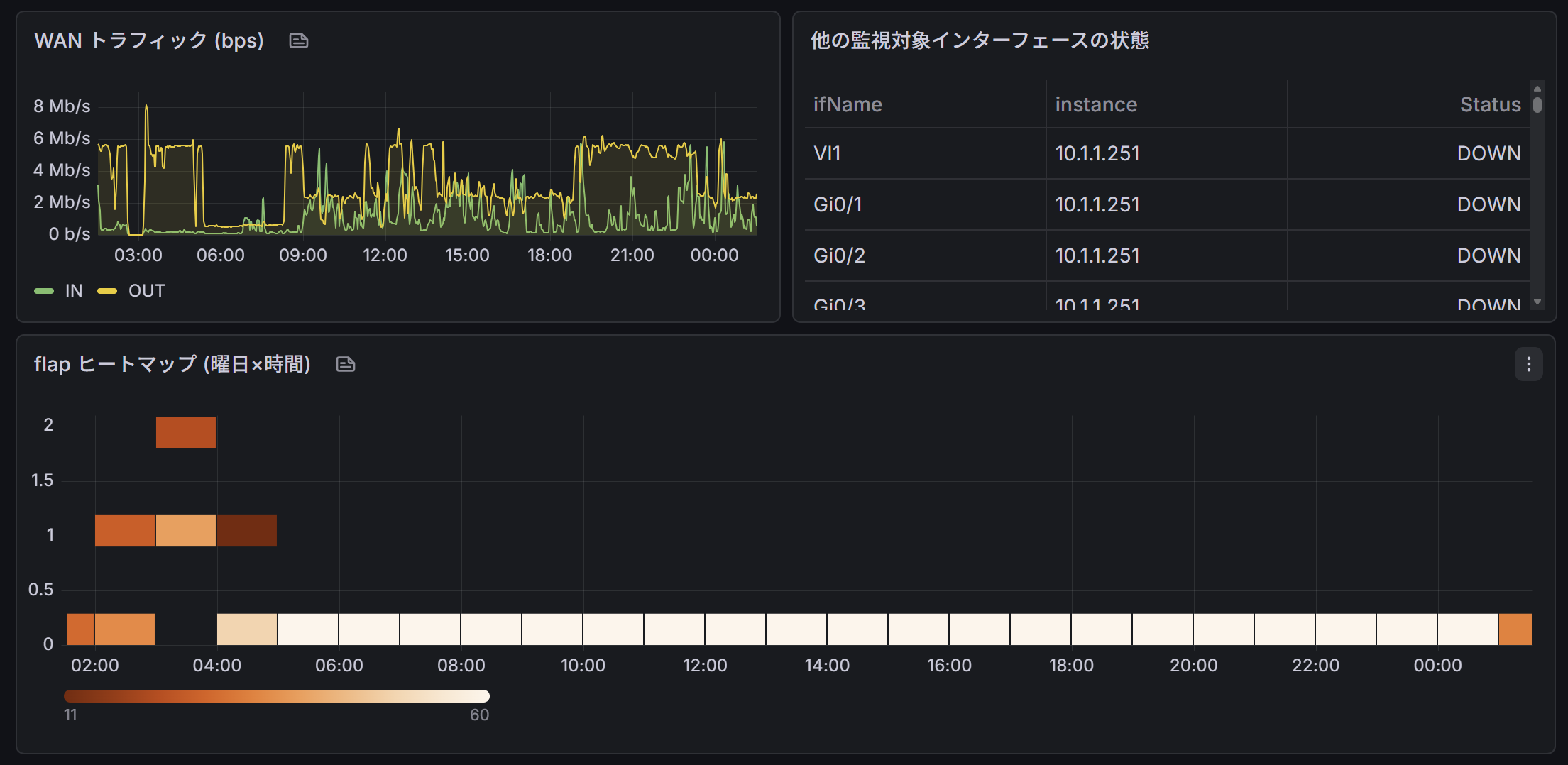
ヒートマップは曜日と時間帯の二軸で flap 数を可視化したもので、規則性を探すのに使います。後述しますが、結果として規則性は出てきませんでした。
ダッシュボード JSON の全量は有料コンテンツ (Grafana ダッシュボード集) 側に置く予定です。本記事では設計判断と PromQL の中身を共有することにしました。
14 日間集めたデータをどう解釈したか
監視を仕掛けてから 14 日経過した時点 (2026-04-27 〜 2026-05-11) で、Prometheus に query_range を投げて 1 時間バケットで集計しました。
GET /api/v1/query_range
?query=changes(ifOperStatus{instance="10.1.1.254",ifName="Gi0/0/0"}[1h])
&start=2026-04-27T00:00:00Z
&end=2026-05-11T12:00:00Z
&step=3600結果のサマリーがこれです。
14 日間の集計
| 項目 | 値 |
|---|---|
| 総 flap 数 | 10 回 |
| 1 日あたり平均 | 約 0.71 回 |
| 最大連続安定時間 | 約 60 時間 |
| 最短間隔 | 約 1 時間 (連続 flap) |
最初の 6 日間で 15 回というペースだったのに対し、14 日間で 10 回。頻度は明らかに減少傾向です。これだけ見ると「直ってきた?」とも思えるのですが、サンプル数が少なすぎて統計的な評価には足りません。
時間帯別の分布
| 時刻 (24h) | flap 数 |
|---|---|
| 00:00台 | 2 |
| 01:00台 | 2 |
| 03:00台 | 1 |
| 04:00台 | 1 |
| 11:00台 | 2 |
| 21:00台 | 2 |
| その他 | 0 |
深夜帯 (0-4 時) に 6 回、昼 (11 時台) に 2 回、夜 (21 時台) に 2 回。「毎日決まった時間に落ちる」というパターンは出ていません。 たとえば「毎朝 9 時に DHCP リース更新で落ちる」のような規則性は見えませんでした。
曜日別の分布
| 曜日 | flap 数 |
|---|---|
| Mon | 4 |
| Tue | 2 |
| Wed | 0 |
| Thu | 4 |
| Fri | 0 |
| Sat | 0 |
| Sun | 0 |
平日寄りには見えるものの、サンプル数 10 で曜日相関を語るのは無理があります。土日にたまたま発生しなかっただけ、と考える方が自然です。
個別イベント
| 日時 | flap 数 |
|---|---|
| 2026-05-04 Mon 21:10 | 2 |
| 2026-05-05 Tue 11:10 | 2 |
| 2026-05-07 Thu 00:10 | 2 |
| 2026-05-07 Thu 01:10 | 2 |
| 2026-05-11 Mon 03:10 | 1 |
| 2026-05-11 Mon 04:10 | 1 |
05-07 の 00:10 と 01:10、05-11 の 03:10 と 04:10 は連続しています。一度落ちた後、1 時間以内にまた落ちるパターン。そして 04-27 から 05-04 までの 7 日間、05-08 から 05-10 までの 3 日間は flap 数 0 でした。
このデータが何を示しているか
ここが記事の山場です。素直に読み解くと、次のような解釈ができます。
1. 規則性は出てこなかった
毎日定刻に発生するわけでも、特定曜日に集中するわけでもありません。サンプル数が少ないので「無い」と断言はできませんが、少なくとも 14 日間の観測では、ソフトウェア要因 (cron, スケジューラ, ISP 側の定期処理) を示唆するパターンは見えませんでした。
2. クラスタ性 (連続発生) はある
一度落ちると 1 時間以内にもう一度落ちることがあり、そのあと数日安定する、という挙動です。これは温度変化や、家族が回線まわりを通った時の物理的な揺れなど、外乱に対して接点が一時的に不安定になるシナリオと整合します。
3. ランダム性自体が手がかり
「パターンが出ない」ことを失敗と捉えがちですが、今回の文脈では違います。マンション設備の JJ コネクタによる接触不良という仮説に対しては、ランダムに発生し、クラスタ性があり、規則的なトリガーが見えないというのはむしろ整合的な証拠です。機械的な要因に依存する接触不良は、再現性が低く、温度・振動・経年変化に左右されます。
ただし、これは論理的には「ランダム性 = 接触不良の証明」ではありません。他の要因 (例: ISP 側のメンテナンスがランダムなタイミングで入る、対向 ONU のファームウェアの問題、宅内配線の途中にある別の接続ボックスでの不調) の可能性は残っています。**「JJ 仮説と矛盾しない」**という以上のことは、今のデータからは言えません。
次のアクション: 物理層に触れる
データはここまでで、ここからは物理側です。マンション設備の JJ そのものに触ることはできないので、自分の手の届く範囲で接点の品質を上げることにします。
記事公開時点 (2026-05-11) では、これから実施するアクションです。
1. WAN ケーブルを Cat6A 短尺ストレートに新調
既存の WAN ケーブルはカテゴリ表記が読めなくなっており、Cat5e か Cat6 か判別不能です。長さも取り回しの都合で曲げ癖がついており、見た目の劣化が目立っています。
これを Cat6A の 1m〜1.5m シールド付きスリムケーブルに交換します。長さを最小限にすることで、不要な引き回しでのストレスを減らせます。Cat6A まで上げるのは過剰スペックではあるのですが、ホームラボの常用ケーブルを一段格上げするついでに、という位置付けです。
期待する効果は、ケーブル本体の経年劣化や物理ストレスによる接点不良を排除することです。WAN ケーブル交換だけで治るなら、JJ よりこっちが原因だったということになります。
2. RJ45 コネクタの接点清掃
ONU 側、ルーター側ともに RJ45 のジャック内側の金属ピンを清掃します。
- 無水エタノールを綿棒に少量
- 接点復活剤 (タミヤ製 or サンハヤトなどの電子部品用) を、塗布後に余剰を拭き取る
- エアダスターで内部のホコリと水分を完全に飛ばす
期待する効果は、酸化皮膜や微細な異物による接触抵抗の増大を解消することです。家庭内のジャックは常時通電しているとはいえ、長期間使うと特に金メッキ層の薄い安物コネクタでは酸化が進みます。
3. 今回はやらないこと (制約)
- JJ コネクタの撤去: マンション設備側に手を入れることになるので不可
- 対向 ONU 側のジャック交換: 同上
- ケーブルテスター (Fluke MicroScanner² 等) での導通テスト: 機材コストが高く、今回は手持ちのケーブルを総入れ替えする方が早い。次の機会の検討課題
JJ そのものが原因なら、自分側のケーブル交換と接点清掃では治らないはずです。治らなかった場合は、マンション側の管理組合や設備業者に対する交渉材料として、今回のデータがそのまま使えます。「14 日間で 10 回、特定の規則性なくランダムに発生している」というデータは、設備側に動いてもらう根拠としては悪くないはずです。
続編予告
物理交換後の 2〜4 週間で再度 Prometheus データを取り、before / after の比較を続編記事で書く予定です。シナリオは三つ。
| シナリオ | 結論 | 続編の方向性 |
|---|---|---|
| flap が完全に消える | ケーブル or コネクタ要因確定 | 自宅側で完結。ケーブル品質の重要性まとめ |
| 変化なし | マンション設備側 (JJ 含む) の問題確定 | 管理組合への交渉材料化、設備側の改善依頼 |
| 悪化する | 別要因 (電源、対向 ONU、宅内中継ボックス等) | 切り分けを継続。ONU 自体の交換依頼まで含めて検討 |
どのシナリオに転んでも、続編は書けます。続編記事のリンクは公開後にここに追記します。
教訓
最後に、ここまでの作業で得た汎用的な学びを 4 つにまとめておきます。
- 物理層の問題は SNMP の if カウンタに必ず痕跡が残る。
lost carrierとCRCとgiantsは最初に見るべきトリオ。reliability 255/255は嘘ではないが、低頻度の障害には鈍感 - snmp_exporter は
walkだけでなくmetrics:セクションも必須。書き忘れると scrape は通るのに値が出ない、という分かりにくい失敗をする。snmpwalkで直接 OID を叩いて切り分ける癖をつけると早い changes(metric[range])は flap 検知のデファクト。for: 1mと組み合わせれば誤検知も減らせる。rate()ではなくchanges()を使うのがコツ- 規則性が出ないこと自体がデータ。「パターンが出なかった」と落ち込むのではなく、「ランダム性が観測されたという事実」として仮説の補強に使える。ただし、それで原因を断定はしないこと
監視を構築すると、いつも「データを集めれば原因が分かる」と期待してしまいます。実際にはデータは選択肢を絞ってくれるだけで、最後は物理に触りに行くしかない、ということを今回あらためて思い知りました。
続編で「治った / 治らなかった」を報告できるよう、まずはケーブルと接点清掃から始めます。
補助資料: PDF レポートとデータセット
本記事の集計データ・設定ファイル・PromQL クエリ一覧・観測運用の落とし穴を 16 ページの PDF レポートにまとめ、CSV データセットと併せて公開しています。CC BY 4.0 で出典明記の上、自由に複製・引用可です。
- 📄 家庭 WAN 安定性レポート 2026 (PDF, 16 ページ) — Cisco C1111 マンション備え付け回線を 14 日間 SNMP 観測した記録
- 📊 wan-stability-2026-dataset.csv — 累積カウンタ差分 + 個別 flap イベントの生データ
関連リンク
- ナレッジ DB: snmp-exporter
if_mibモジュールでmetrics:欠落の罠 (d7459313-6895-4700-a151-faeff161acc6) - ナレッジ DB: Cisco C1111-X の WAN ポート (Gi0/0/0) は TDR 非対応 (
482c7daa-8366-45b8-b754-143c290cbf55) - 過去記事: Raspberry Pi + LINE + Cisco AP で WiFi 自動チャンネル変更
- 過去記事: WiFi が不安定だった話 — Cisco AP / Nest Mini / Meraki の三つ巴
自宅サーバとネットワークの観測の全体像は 自宅 Observability の完全ガイド — Prometheus + Grafana + Loki で家のサーバとネットワークを観測し続ける にまとめています。監視基盤の設計判断から複合障害・retention 運用までを 1 ページで通読できる Pillar ガイドです。
コメント